未病予防事業の成長可能性について
健康経営や、ヘルスケア産業の文脈における社会的な認知は、進んできました。健康のままQOLの高い人生を送ることに日本全体が進むべき方向にあると云われている。
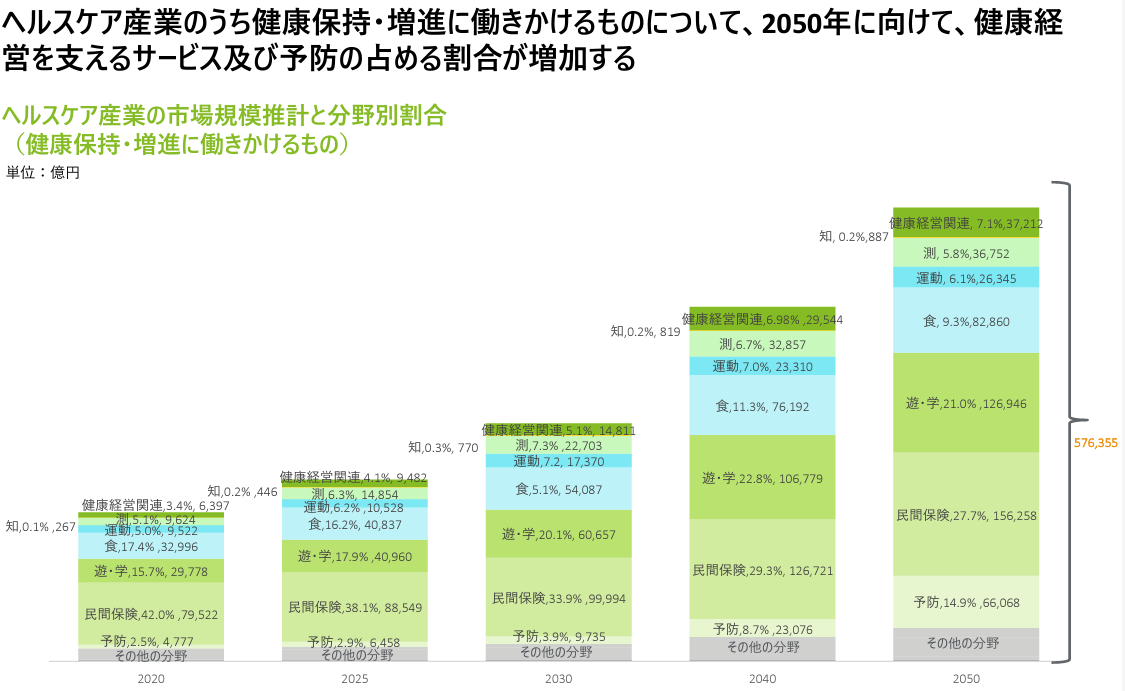
上記は、経済産業省がまとめる、ヘルスケアサービス社会事業の売上予測です。
高齢化に伴う社会保障の観点から、政府は65歳、あるいは70歳以上になっても、社会的に繋がり続けて、できれば長く働き続けることを期待しているようです。私たちは、病気を予防し、未病のまま、これに応え続けたいと考えます。
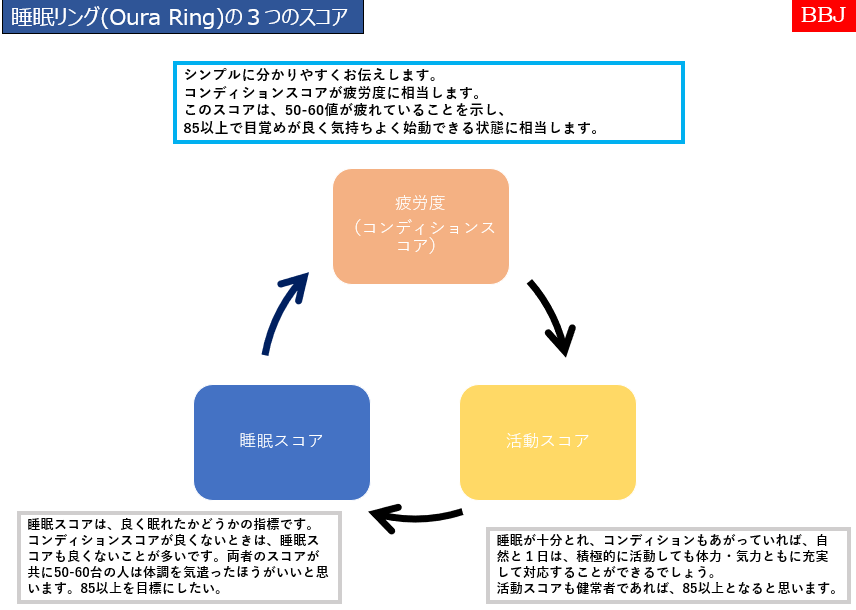
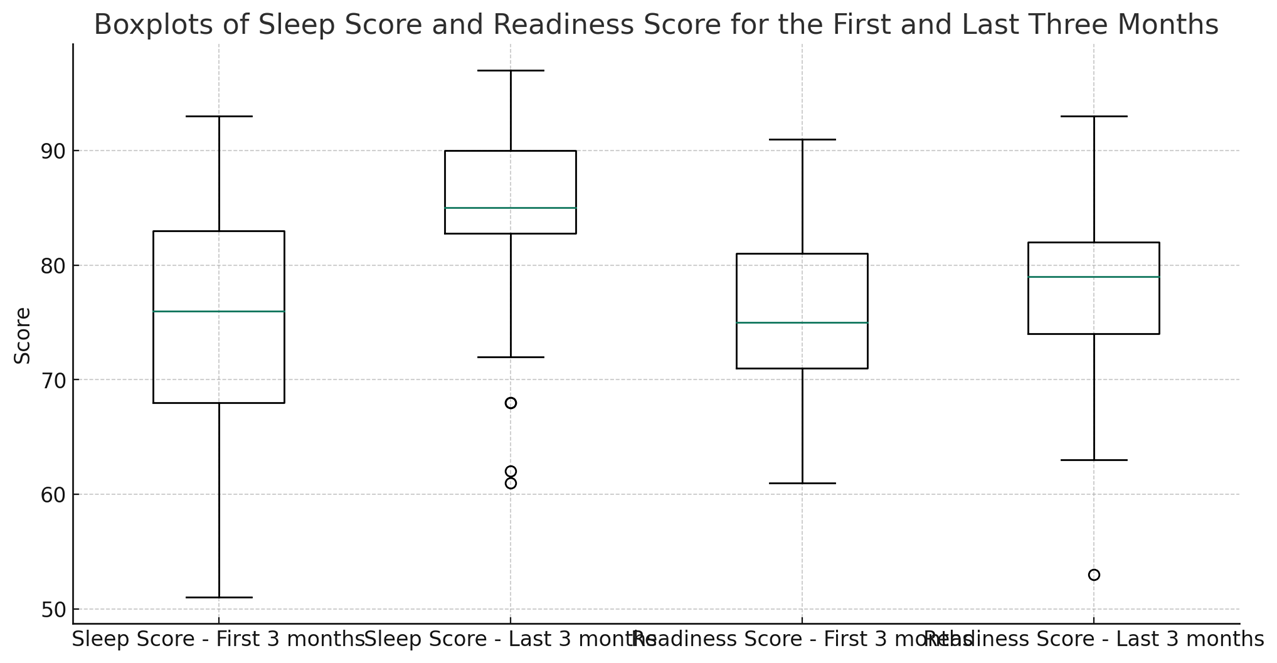
生体情報を測定するスマートリング・睡眠リングについては、この図の測定(上から2番目)と予防(下から2番目)に該当する領域に該当すると考えております。
ヘルスケア産業の概念図の真ん中に、現在の医療分野の領域が入っています。その周りを取り囲む領域(薄い緑色)が、ヘルスケア産業の対象領域です。
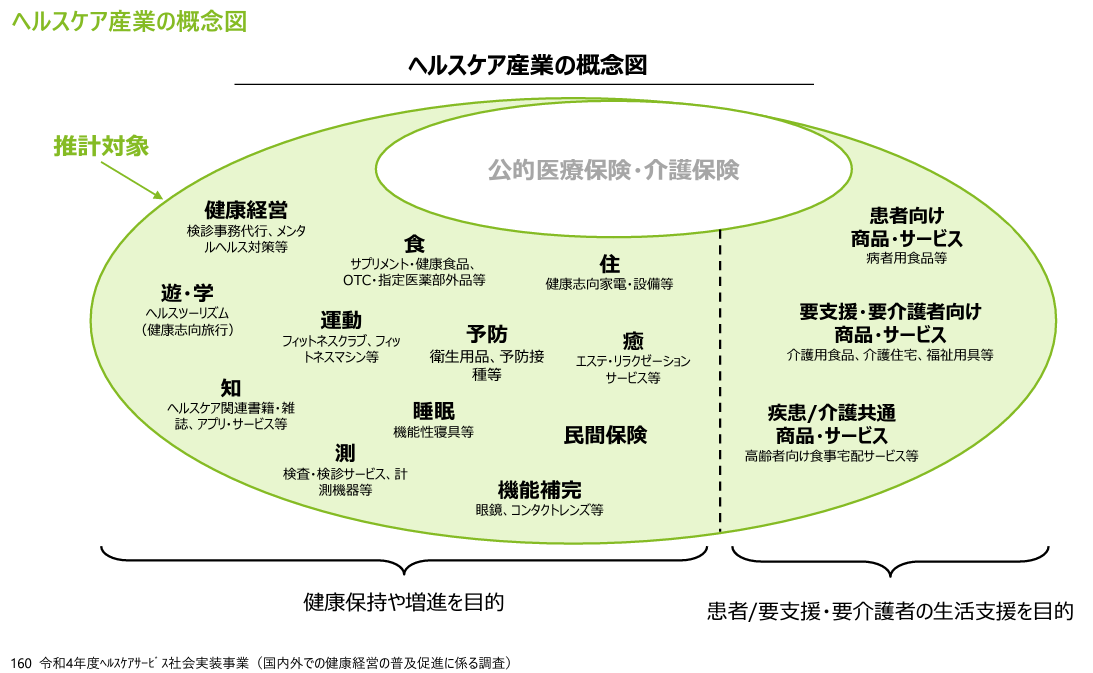
新しい健康社会の実現に向けた「アクションプラン2023」(案)の4頁目には、色付けされた同内容の図が見えます。社会全体で、健康保持と増進を目的として捉え直す機運を感じています。
これまでは、病気になってから医療で治す部分に大きな投資がなされてきましたが、これからは病気になる前から病気にならないようにするために、投資するという考え方の必要を同時に感じられます。
滋賀医科大学の矢野裕一郎教授らは、健康経営の会社を対象に大規模調査を実施してまとめておられます。
分析対象は、1,593社(従業員数4,359,834人)であり、従業員の平均年齢は40.3歳、女性比率は25.8%であった。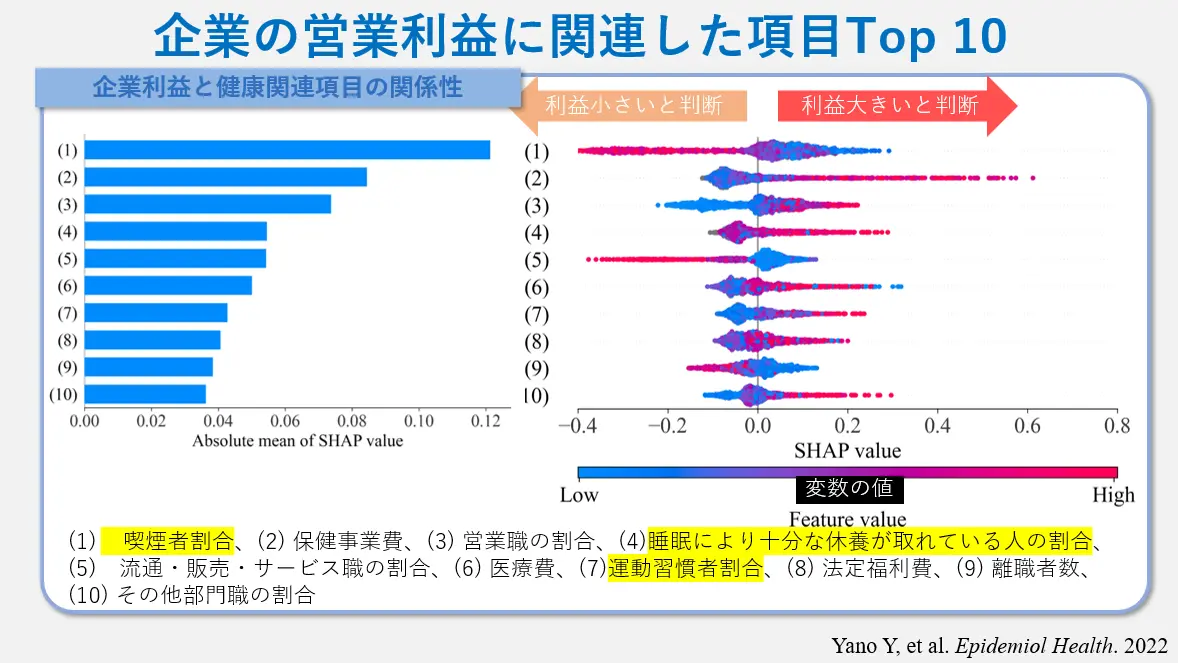
日本の企業の営業利益と健康関連項目の関係を調査した結果です。その結果、以下の項目は営業利益と正の相関があり、営業利益が高い企業ほど、これらの項目の値が高くなる傾向があることがわかりました。
- 喫煙者割合:喫煙者の割合が低い企業ほど、営業利益が高い。
- 睡眠により十分な休養が取れている人の割合:睡眠により十分な休養が取れている人の割合が高い企業ほど、営業利益が高い。
- 運動習慣者割合:運動習慣者の割合が高い企業ほど営業利益が高い。
また、以下の項目は営業利益と負の相関があり、営業利益が高い企業ほど、これらの項目の値が低くなる傾向があることがわかりました。
- 医療費:従業員1人当たりの医療費が高い企業ほど、営業利益が低い。
- 離職者数:離職者数が多い企業ほど、営業利益が低い。
しかしながら、日本人全体の睡眠時間を各国と比較しますと、いまだに、諸外国の最下位6時間10分です。(OECD報告で年変動はあるが、上位国との差異は同じ)
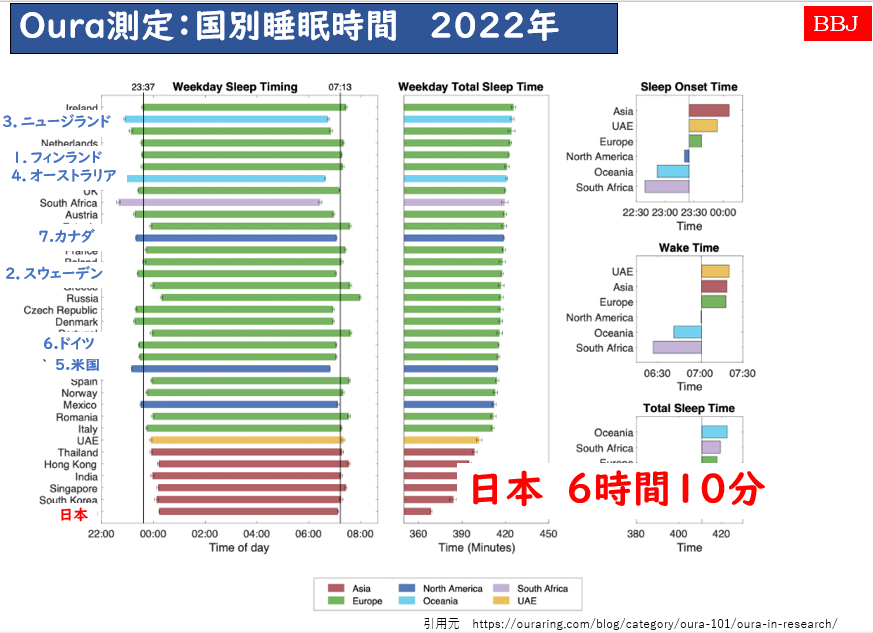
引用元 https://ouraring.com/blog/category/oura-101/oura-in-research/
私たち日本人の目標としてそろそろこのワーストから脱すべき時期にきているのではないでしょうか。
睡眠時間が短いことを自虐的に伝えることを、そろそろ止めにしませんか。しっかりと十分に睡眠を取った企業のほうが、業績が高いという成果が出始めているのですから、そろそろしかるべく時間を眠るように社会全体を動かしていくことが大切ではないでしょうか。
以下は、OECD.org から ChatGTPでグラフにしたものです。一日24時間を何に使っているのかというパート別に分けた内容で、日本は最左の青線に位置します。これをみますと、労働が突出しています。だいたい諸外国と比較して、70-90分ほど多い。その分、無給労働と、睡眠が削られているように見えます。
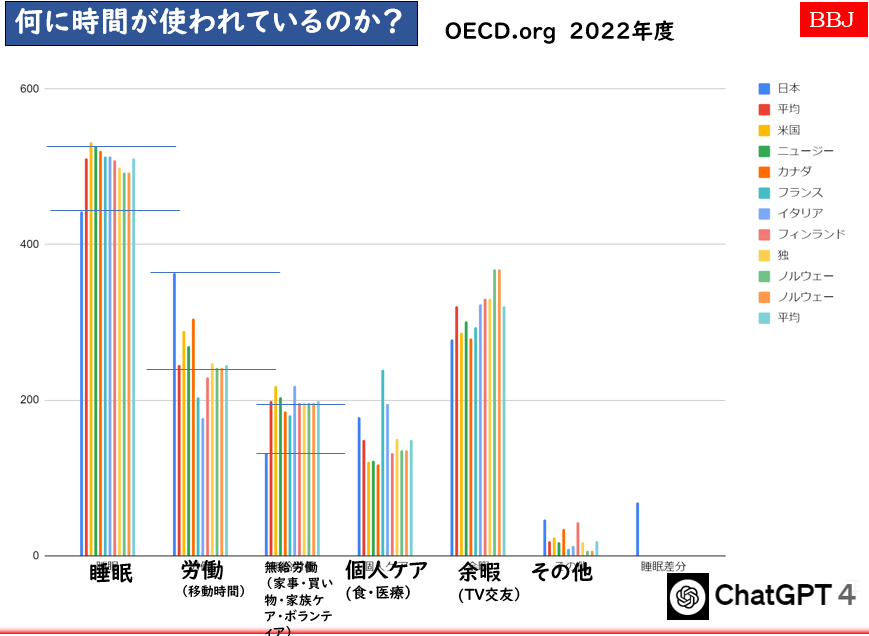
生活時間比較
以下の図は、2018年と少し古いデータですが、縦軸が睡眠時間、横軸が一人当たりGDPです。諸外国と比較して、一人当たりのGDPも低いままで、睡眠も削って頑張る日本という姿が垣間見えます。
しかし裏を返すと、諸外国のほとんどは、日本人よりも60-90分も良く寝ており、さらに一人当たりのGDPも高いので、とても効率が良く働いて稼いでいるように見える。よく眠りながら、短時間に働いていることが読み取れます。
つまり、この事実から、睡眠を削って働くというこれまでのやり方そのものが、先進諸国と比較して、だいぶ遅れている考え方であると気づきます。
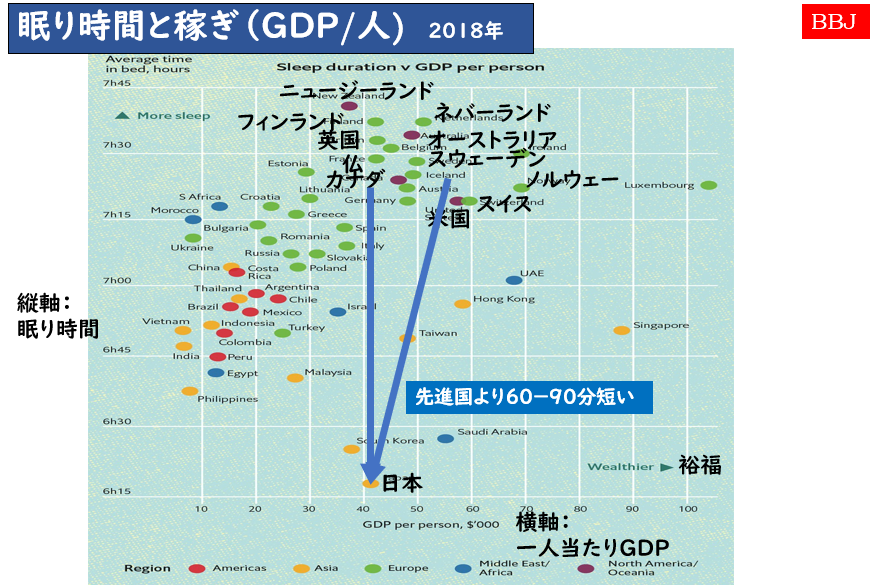
この図は単なる相関関係を示した話であって、(睡眠が短い⇒一人GDPが低い理由にならない)因果の説明になってないと思われた方もいらっしゃることでしょう。私も、当初そう思っていました。ところが、慶応大学の山本教授のご研究により、因果関係について説明をしているように見えます。

調査した会社や対象領域にある社員のデータから、睡眠時間が伸びると、利益率変化(直近・一年後)が高いことを導きだしています。
この事実は、十分な睡眠時間が取れて眠れている方は、日々回復ができているわけですから、一日の活動度も上昇するということで、そうしたコンディションの良い社員が、たくさんいる企業が業績が高まるというのは、ごくごく自然に考えられます。
そして、眠れていないことに対する日本全体の遺失利益を示した報告書もあります。
2016年Rand研究所の発表によると、日本は眠れてないということだけで、20兆円もの損害を被っているという内容です。これは労働生産人口で割ると、労働者一人あたり26.7万円となります。もしも100名の事業者であれば、2670万に相当するため、本来得られたはずの利益であると考えると、とても大きく感じます。

引用元 https://www.rand.org/pubs/research_reports/RR1791.html
この事実から、睡眠とコンディションへの企業の投資が行われることに繋がると予想できます。
ここまでで、諸外国より1時間以上眠れてない日本は、睡眠時間最下位という状態にあることで、本来創出できた富を遺失する事実を、目にしました。睡眠時間を確保して時間と質の良い睡眠を確保したほうがいいのです。
ここから、私たちができることは何かですが、シンプルに言うと、
**もう1時間余分に眠るです。Let’s Sleep for One More Hour.

Let’s sleep for one more hour
それが実現されたとき、皆さんが元気になって、日本に活力が戻ってくる。**
自身の睡眠を理解して、生活を改善してみてはどうかと思います。
健康経営とは、従業員の健康を経営戦略の一部として捉え、健康に関する取り組みを積極的に行うことです。健康経営を行うことで、従業員のパフォーマンスや満足度、ロイヤリティが向上し、組織の生産性や競争力が高まります。
健康経営の取り組みの一つとして、睡眠リング(oura)を導入することをおすすめしています。 睡眠リングは、睡眠、心拍数、体温などの健康データを正確に測定することができる指輪型の健康トラッカーです。このようなデータは、従業員の健康状態を把握し、改善するために役立ちます。
睡眠リングは、従業員の健康管理だけでなく、メンタルヘルス管理や組織のエンゲージメント向上にも役立つツールとして活用することができます。従業員に自分の健康データを共有する機能も備えています。これにより、従業員同士や上司と部下などのコミュニケーションやフィードバックが促進されます。これは、従業員のエンゲージメントやチームワークを高める効果が期待できます。
Oura社とパートナーシップを築いてきた取扱店として、私たちは睡眠リング(Oura Ring)の販売に力を入れています。睡眠リング(Oura Ring)は、従業員の健康管理やメンタルヘルス管理、エンゲージメント向上など、様々な用途に活用することができます。
健康経営における睡眠に関するサービスをご要望の方がいらっしゃいましたら、ご相談、お待ちしております。睡眠リングを使って、従業員の健康と幸せを守りましょう。

Let’s sleep for one more hour