
時系列データは、リザバーコンピューティング(RC)で解く その2です。
RCリザバープールノードの重み値は固定・修正しない??の意味が掴めないので、感覚として捕まえるために、少し手を動かして、遊んでみることにした。githubで、reservoir-computingを確認すると、20数件のサンプルが見つかる。その中から、EchoTorch と、simple echo state network を動かした。
時系列予測のベンチマークとしてNARMA10の4000データで学習して、1000データを予測。自分PC(iCore7)でも、数秒で結果が得られる。
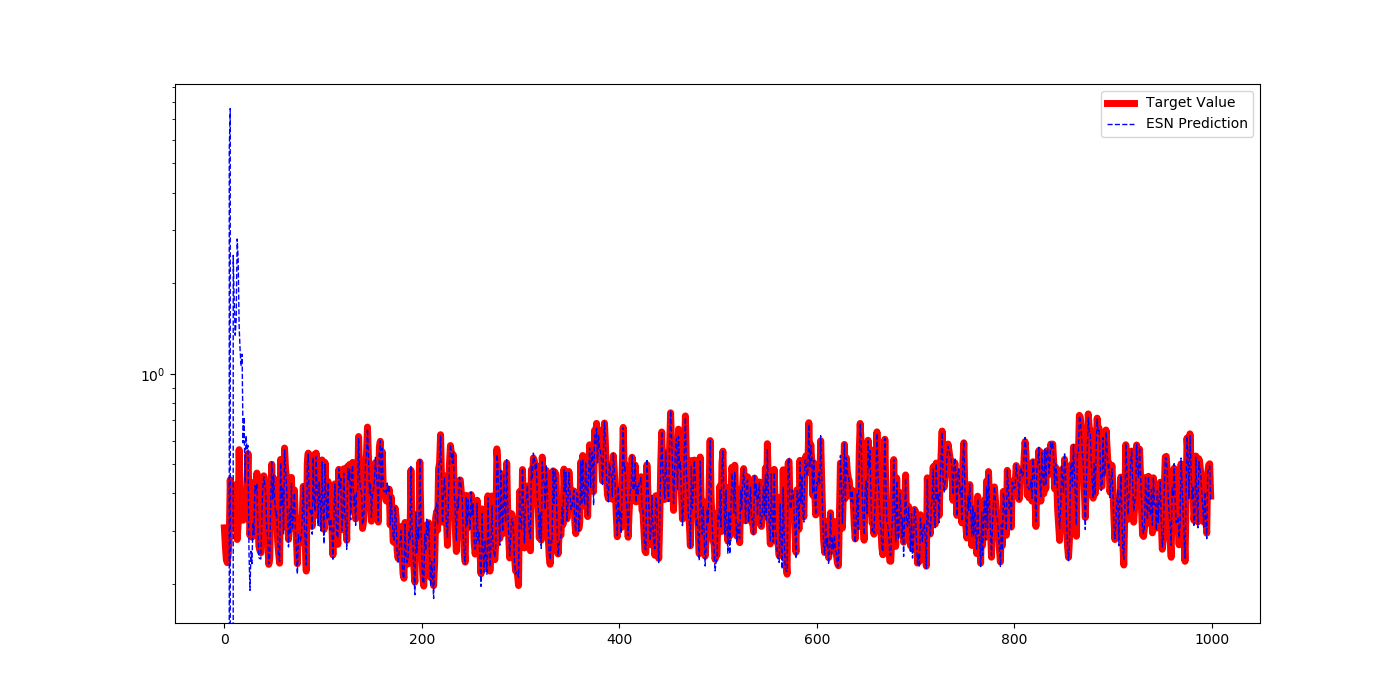 すぐにモデルにフィットし、予測値にずれがあるようには見えない。その時の、アクティビティの出力結果は、毎回実行するたびにノードの出力は変わるものの、予測誤差がない。これは、なかなかの印象です。
すぐにモデルにフィットし、予測値にずれがあるようには見えない。その時の、アクティビティの出力結果は、毎回実行するたびにノードの出力は変わるものの、予測誤差がない。これは、なかなかの印象です。

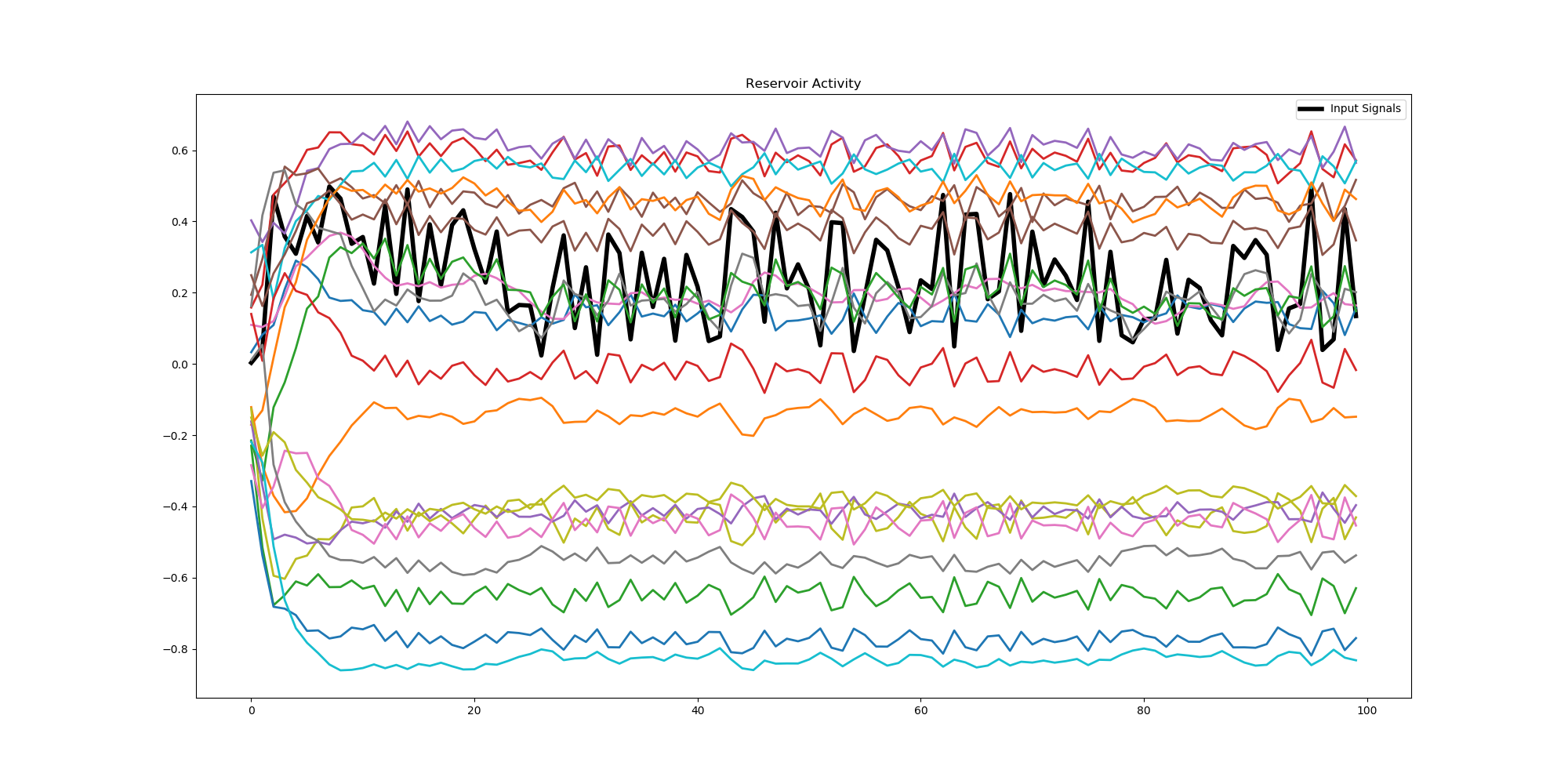
そしてリザーブプールノードの重み値が変えない恩恵だが、学習時間が短い。このケースでも、IoTセンシングのサンプリングレート100Hz (100msec)なら、4000ポイントであれば、40秒+αで学習できそうな印象。何やら、たくさんのGPUユニットに深いノードで、収束させるのに比べると、このライトな感じは一体・・・・
時系列データパターンの何を教師データとして見抜かせるのか、パターン周期のどこをポイントにするかは、こちらの利用しやすい場所をいかに指示するかにより、その実装センスを持ち合わせる技術者が必要になる。
いま私は、睡眠の解析をしていて、ノイズありの時系列データからあるパターンの特徴抽出したい。そして、この技術を適用できるかもしれない。
もちろん、非線形ダイナミクスを表現する内部ノード構成、時系列パターンにマッチさせるノード構成は、今後の研究を待つことになろうが、現時点でも実用的なサービスに落とし込めそうな感じのする技術であるリザバーコンピューティングは、IoTセンサーや時系列データに応用できそうである。